

1. はじめに:ヘテロジニアスなアクセラレータ時代に向けて
AIワークロードの多様化に伴い、計算基盤に求められるものも変わりつつあります。
大規模なクラウド学習クラスタだけでなく、エッジでの推論、マルチエージェントシステムの協調動作、Physical AIへの適用など、AIの実行環境はますます分散し、多層化しています。そして、それを支えるアクセラレータもまた、NVIDIA GPU、AMD GPU、各種NPU、さらにはCPUまで、用途とコストに応じて使い分けるヘテロジニアスな構成が現実のものとなりつつあります。
Midokuraは、こうした多様なアクセラレータをEdgeからCloudまでシームレスに組み合わせ、AIワークロードを最適にディスパッチする基盤の実現を目指しています。 その構成要素の一つとして、本記事では AMD GPUのKubernetes上での仮想化 に取り組んだ成果を紹介します。
2. 問題:1 GPU = 1 Pod の非効率
KubernetesにおけるデフォルトのGPUリソース管理は、MIGやvGPUなどの仮想化機能を有効にしない場合、 「1つのGPUを丸ごと1つのPodに割り当てる」というモデルです。
しかし、推論ワークロードの多くはGPUの計算能力やメモリの一部しか使いません。たとえば、大容量のVRAM(数百GB級)を備えた高性能GPUに対して、数GBしか使わない推論サーバが1台だけ動いている――そんな状況も起こり得ます。
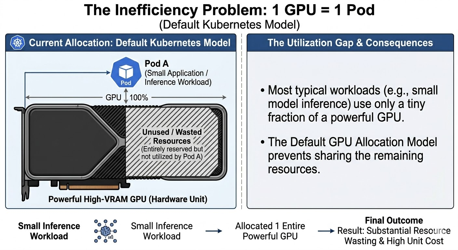
一部のGPU(例えばNVIDIA)ではMIG(Multi-Instance GPU)やvGPUなどの仮想化が選択肢として存在します。
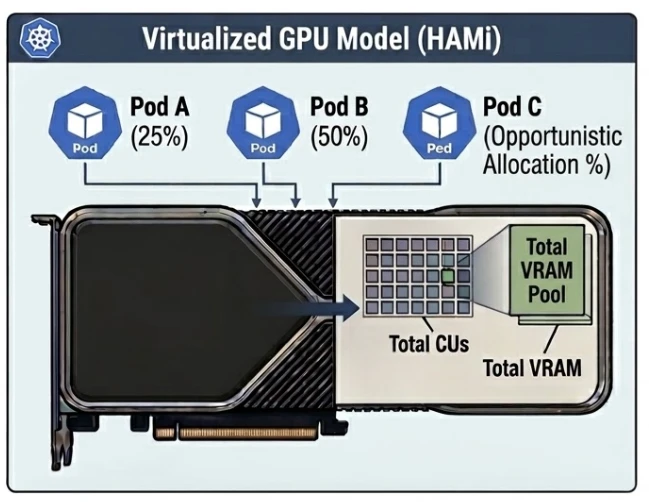
3. HAMiにAMDサポートを追加する
HAMi(Heterogeneous AI Computing Virtualization Middleware)は、KubernetesにおけるGPU仮想化のためのオープンソースミドルウェアです。CNCF Sandboxプロジェクトとして採択されており、NVIDIA GPUの仮想化に実績があります。
特に評価できるのは、その拡張性に優れた設計です。統一されたスケジューラ拡張機構と、各アクセラレータごとに異なるデバイスプラグインおよび仮想化技術を組み合わせることで、新しいデバイス対応を効率的に追加できる構造になっています。実際、すでにNVIDIA、Cambricon MLU、HYGON DCU、Iluvatar、Moore Threads、HUAWEI Ascend、MetaXなど、多くのベンダのアクセラレータに対応し、50社を超える企業や機関で採用されています。
このHAMiにはAMD GPUのサポートがありませんでしたが、こうした成熟した設計を活用することで、AMD GPUのサポート追加も比較的スムーズに実装できます。
私たちミドクラでは、PoCとして、このHAMiにAMD GPUサポートを独自に実装しました。以下では、AMD Instinct MI300X(192GB VRAM、304計算ユニット搭載)という高性能GPUを実装検証対象とした事例を通じて、その仕組みと成果を説明します。
実現する機能は2つです。
- Compute Unit(CU)マスキング: GPUの演算ユニットを分割し、Pod単位で排他的に割り当てる
- メモリ制限: 各Podが利用できるVRAMの上限を設定可能とする
これにより、1台のAMD GPUを複数のPodで安全に共有できます。
4. 仕組み:GPUランタイムのインターセプト
4.1. LD_PRELOADとLD_AUDIT
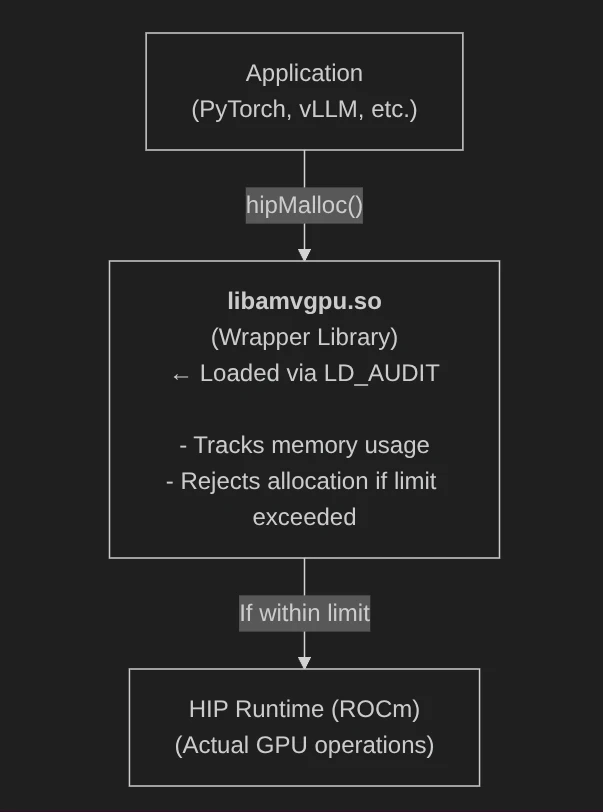
GPU仮想化の典型的なアプローチは、GPUランタイム(NVIDIAならCUDA、AMDならHIP)のAPI呼び出しをインターセプトして、メモリ確保量やデバイス情報を書き換えることです。
NVIDIA GPUの場合、LD_PRELOAD環境変数でカスタムライブラリをプリロードし、これにより適切にAPI呼び出しをインターセプトできます。
AMD GPUでも同じアプローチが考えられますが、初期検証では、ROCmランタイム(HIP)の内部シンボル解決との相互作用管理が複雑になる可能性が見えてきました。そこで、プロトタイプ実装ではLD_AUDITを採用することにしました。
Linuxの動的リンカに備わるこの仕組みを使うと、ライブラリ間のシンボルバインディングをフック関数(la_symbind64)で選択的にインターセプトできます。外部からのHIP API呼び出しだけをラッパーに差し替え、HIP内部の呼び出しはそのまま通す――この選択的なインターセプトにより、ROCmランタイムとの相互作用を最小限に抑えながら、メモリの仮想化を実現できました。
ただし今後、コミュニティのポリシーやユースケースに応じて、LD_PRELOADベースのアプローチへの検討・改善も視野に入れています。
LD_AUDITによるインターセプト:
4.2. CUマスキング:演算リソースの分割
AMD GPUのCompute Unit(CU)の割当は、ROCmが提供するROC_GLOBAL_CU_MASK環境変数で制御できます。我々が作成したHAMiスケジューラは、Pod作成時にGPU上の空きCU範囲を検索し、ビットマスクとして環境変数に注入します。
この設定はROCmランタイムおよびKFDカーネルドライバを経由してGPUハードウェアに渡され、CUの割り当てが実行されます。HAMiスケジューラがCU範囲の重複を防ぐことで、複数のPodが同一GPU上で演算リソースを分割して利用できます。
4.3. Kubernetes統合
ユーザーから見ると、必要なのはPod specに3行追加するだけです。
resources: limits: amd.com/gpu: 1 amd.com/gpucores: 152 # CU数(304中152 = 50%) amd.com/gpumem: 98304 # メモリ上限(MB)
HAMiスケジューラが裏側で以下を自動的に処理します。
- GPU上の空きCU範囲を探索し、ビットマスクを生成
- メモリ上限と合わせて環境変数をコンテナに注入
libamvgpu.soをコンテナにマウント
アプリケーション側の変更は一切不要です。PyTorch、vLLM、Ollama、SGLangなど、HIPを使う任意のフレームワークがそのまま動作します。
注記: 本記事で使用している amd.com/gpu、amd.com/gpucores、amd.com/gpumem というリソース名は、Midokuraの実装プロトタイプで採用した表記です。最終的なKubernetes統合時には、他のハードウェアに対する表記との統一感や、コミュニティで決められた命名規則に従う可能性があります。
5. 検証結果
5.1. スケーリング効率
MI300X上でCU数を変えながら行列演算(8192×8192 FP16)のベンチマークを実施しました。
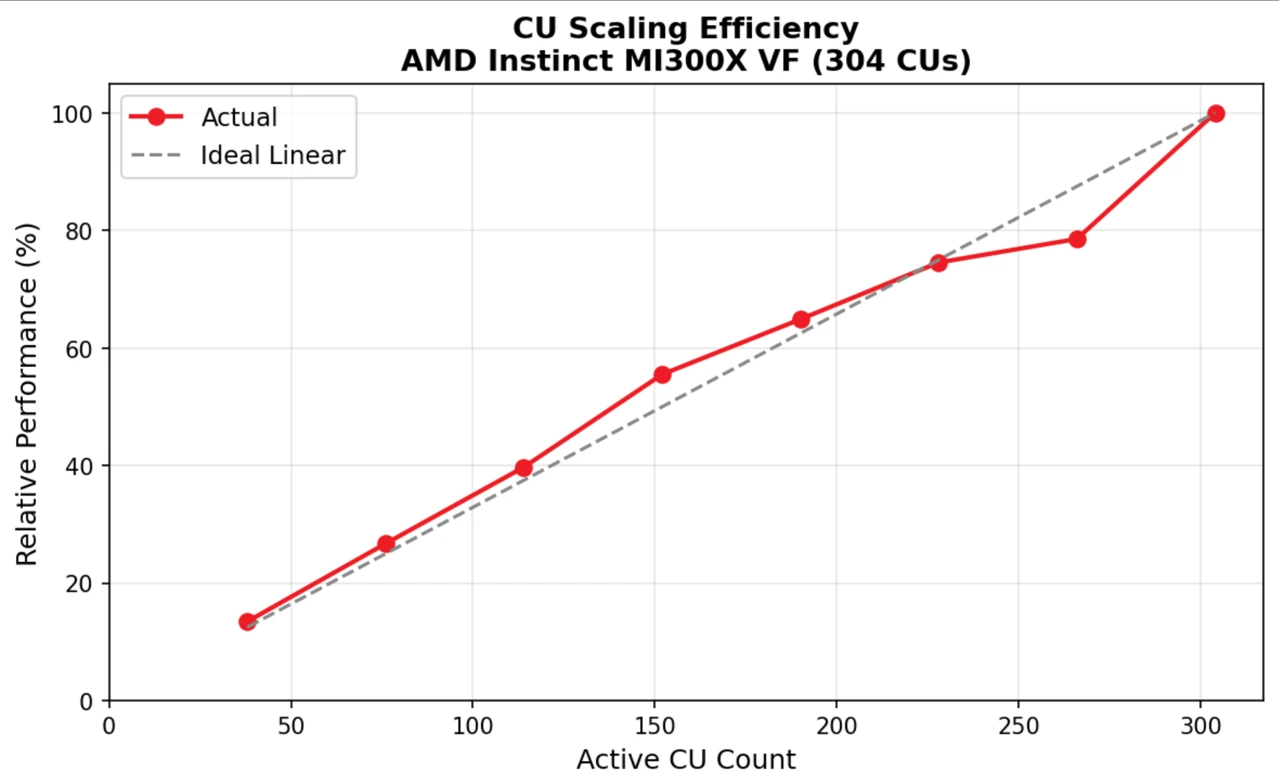
| CU数 | GFLOPS | 全CU比 |
| 38 (12.5%) | 16,076 | 13.5% |
| 76 (25.0%) | 33,338 | 27.9% |
| 152 (50.0%) | 66,284 | 55.4% |
| 304 (100%) | 119,423 | 100% |
CU数に対してほぼ線形にスケールしており、**スケーリング効率は約93%**です。これは、CU数を倍にすれば性能もほぼ倍になることを意味します。
5.2. マルチテナント同時実行
1台のMI300X上で3つのPodを同時に実行し、それぞれが独立したCUとメモリを持つことを検証しました。
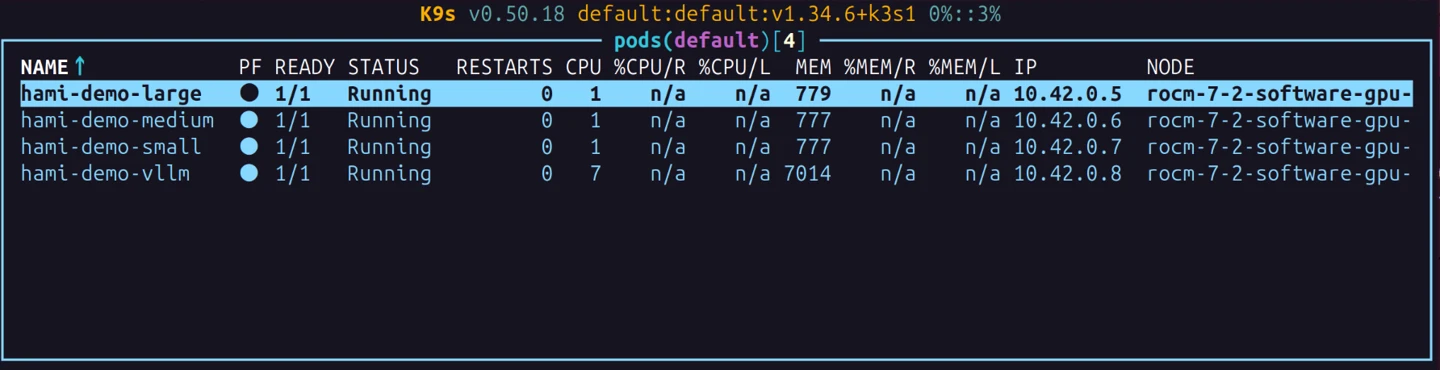
この図のように、hami-demo-large、hami-demo-medium、hami-demo-smallの3つのPodを、それぞれ異なるamd.com/gpucoresとamd.com/gpumemを設定して立ち上げました。
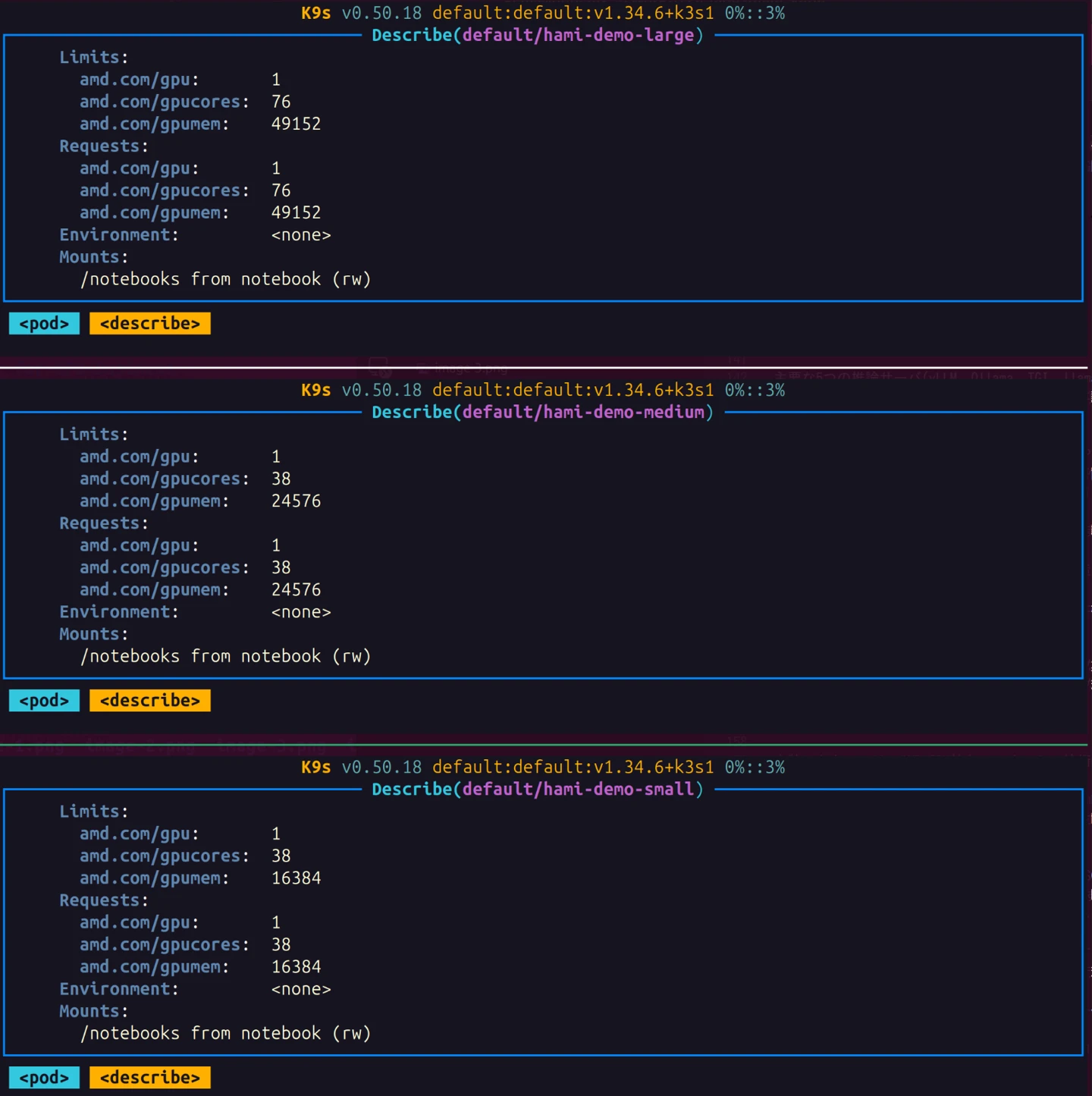
Pod内部のプログラムが上記の設定値を反映した環境で動作していることを確認するために、Jupyter Notebookを用いて検証しています。下記は、テスト用プログラムからの抜粋です。

ここでは、PyTorchのtorch.cuda.mem_get_infoにより、認識しているGPUメモリの情報を出力しています。各Podが物理GPUの全メモリ(192GB)ではなく、amd.com/gpumemで設定された分のメモリのみを認識するはずです。
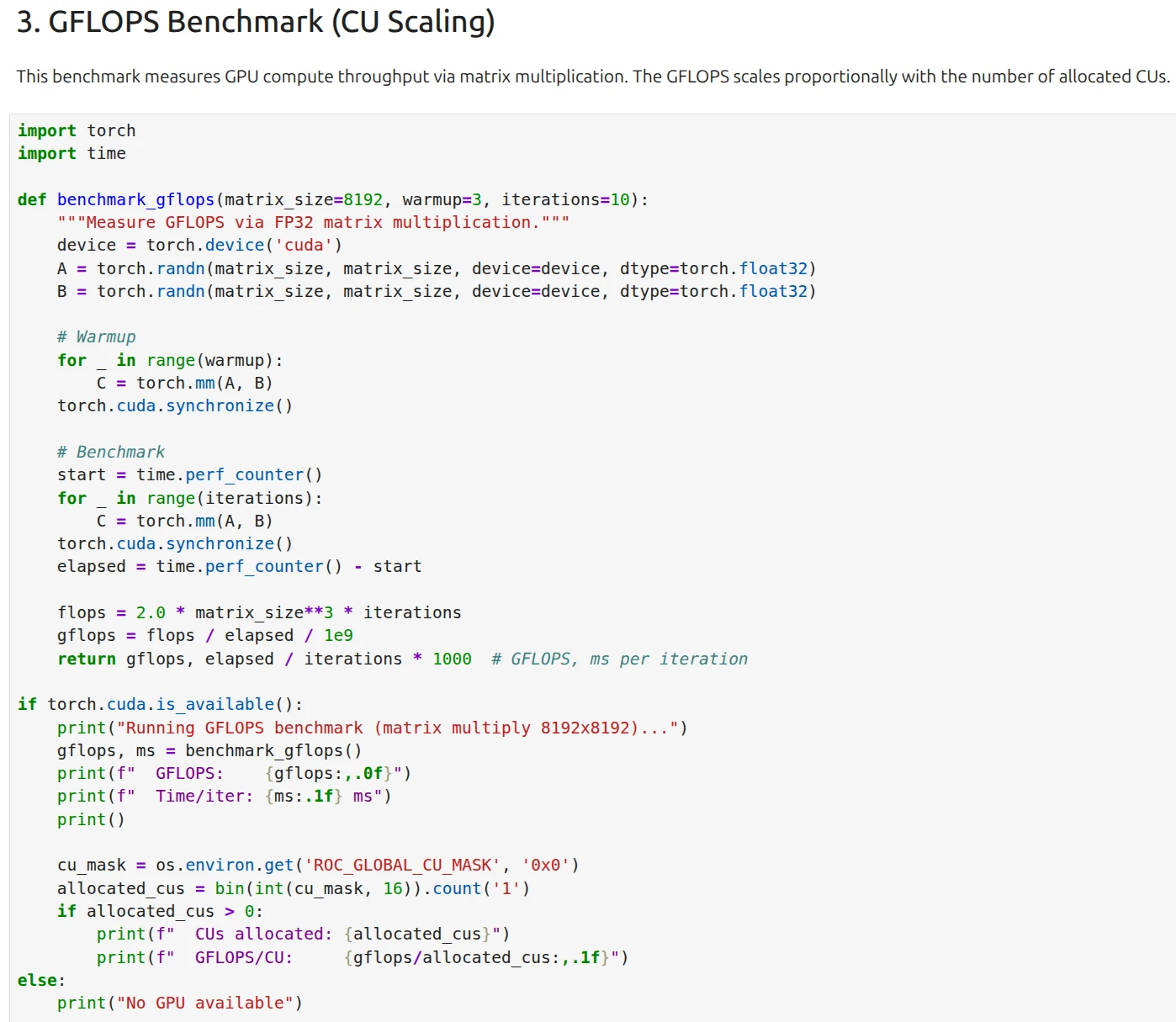
torch.mmにより行列積を繰り返し行い、単純な処理性能を算出して出力しています。amd.com/gpucoresの値により計算に使うCUの数を制限しているので、Jupyter Notebook上で実行した行列積のベンチマーク結果もCU数の影響を受けるはずです。
異なるリソースを割り当てた3つのPodにおける検証結果は下記の通りです。
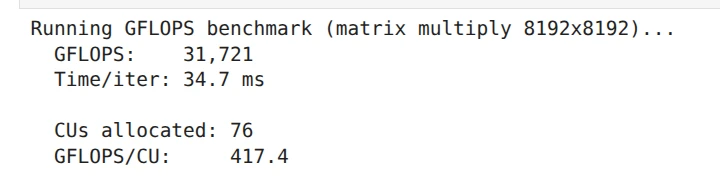
HAMi-demo-Large (gpucores:76, gpumem: 49152)
HAMi-demo-Medium (gpucores:38, gpumem: 24576)
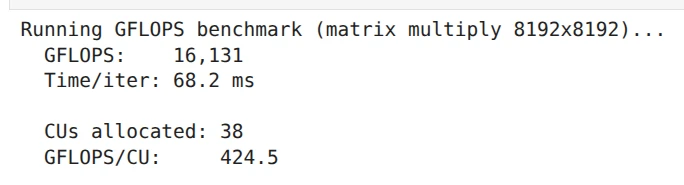
HAMi-demo-Small (gpucores:38, gpumem: 16384)
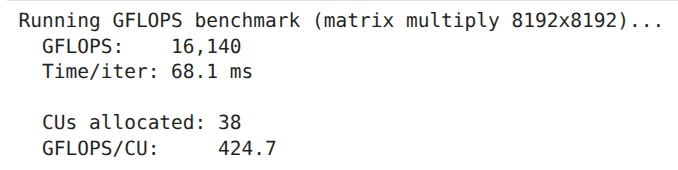
CU数が同一であるHAMi-demo-MediumとHAMi-demo-Smallでは、GFLOPSの値がほぼ同一で、CU数が2倍であるHAMi-demo-Largeでは、GFLOPSの値が2倍弱になっていることがわかります。
また、PyTorchが認識しているメモリサイズも設定された量のみに制限されていることがわかります。例えば、HAMi-demo-LargeにおけるGPUメモリの割当サイズは、49152 × 1024 × 1024 = 51539607552(約51.5 GB)です。
5.3. 推論サーバ互換性
主要な5つの推論サーバ(vLLM、Ollama、TGI、llama.cpp、SGLang)で検証を実施しました。すべての推論サーバに対して、以下の共通テスト項目を実施しています。
共通テスト項目(全サーバ):
- hipMemGetInfo仮想化: メモリ制限がHIP APIで正しく認識されることを確認
- 正常推論: メモリ制限内での実際の推論動作を検証
- OOM制御: 割り当て上限を超えた場合、HAMiが確実にメモリ割当を拒否することを確認
さらに、共通テスト項目に加えて、各推論サーバの実装の違いを踏まえた追加確認も行っています。
- vLLM, TGI: プロセスを複数立ち上げる構造のため、CUマスクとメモリ制限が子プロセスに正しく伝搬することを確認しました。
- SGLang: マルチワーカー構成でKVキャッシュが制限内に収まることを確認し、メモリ制限がワーカー全体に波及することを検証しました。
以上の検証により、各フレームワークはサーバ側の改修なしに、仮想化されたメモリとCUを正しく認識し、リソース制限内で安定動作することが確認できました。
6. 実装上のポイント
実装にあたって直面した、AMD GPU特有の技術的ポイントをいくつかご紹介します。
マルチプロセス推論サーバへの対応:vLLMやSGLangは子プロセスをexecで起動する際に環境変数をリセットするため、CUマスクやメモリ制限が消失する問題がありました。コンテナのPID 1の環境変数(/proc/1/environ)から復元する機構を実装しました。
glibc互換性:ROCmのバージョンごとに要求するglibcが異なり、単純なビルドではバイナリ互換性が破綻します。シンボルエクスポートを制御するラッパーヘッダで対処しました。
7. 今後の展望:ヘテロジニアスなアクセラレータ基盤へ
今回のAMD GPUサポートは、私たちが目指すヘテロジニアスなアクセラレータ基盤の最初のピースです。
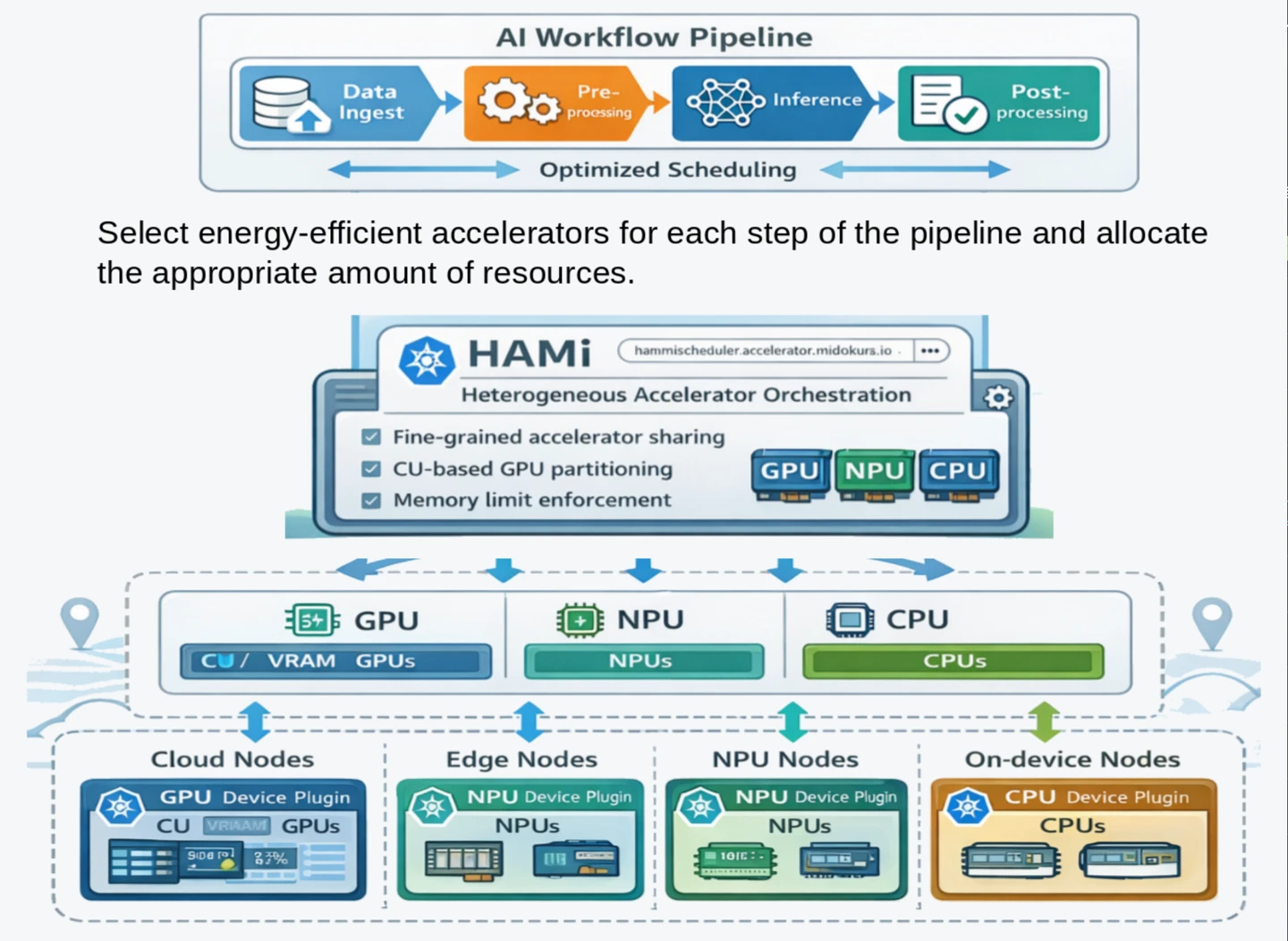
様々なベンダのGPU、NPU、そしてCPUを、ワークロードの要件とコスト効率に応じて適切に組み合わせ、EdgeからCloudまでの全レイヤにわたってAIワークロードを最適にディスパッチする。マルチエージェントシステムやPhysical AIといった次世代のAIアプリケーションが、インフラの差異を意識せずに動作できる世界を実現していきたいと考えています。
本記事で紹介したAMD GPU仮想化の成果は、プロトタイプ実装で終わらせず、HAMiプロジェクトのコミュニティと連携しながらコントリビュートしていきたいと考えています。 すでにNVIDIA GPUをはじめ、ヘテロジニアスなアクセラレータに対して実績のあるHAMiのアーキテクチャやベストプラクティスを尊重し、全体との統一性を踏襲した形での貢献を目指しています。また、将来的には他のベンダのアクセラレータへの拡張も見据えた設計となっていることを確認し、エコシステム全体の発展に寄与できればと考えています。
参考情報
- HAMi – Heterogeneous AI Computing Virtualization Middleware – CNCF Sandbox プロジェクト
- ROCm Documentation – AMD GPU ソフトウェアプラットフォーム
- AMD Instinct MI300X – 検証に使用したGPU