


1. はじめに:なぜ今、KVCacheの「仮想化」なのか?
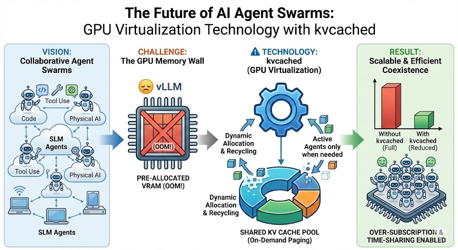
生成AIのトレンドとして、単一の巨大な大規模言語モデル(LLM)だけでなく、特定のタスクに特化した多数の小規模言語モデル(SLM)が連携する**「マルチエージェント・システム」**というアプローチが広がり始めています。
私たちミドクラが描くビジョンは、クラウドからエッジ(Physical AI)まで、環境を問わず無数のAIエージェントが協調してタスクを解決する世界です。そこでは、コーディングが得意なエージェント、特定のMCP(Model Context Protocol)ツールにアクセスできるエージェント、物理デバイスを制御するエージェントなど、様々なドメイン知識を持ったエージェントが、あたかも1つのチームのように振る舞います。
しかし、このビジョンを実現するためには、超えなければならないハードルがあります。**「GPUメモリ(VRAM)リソースの不足」**です。 例えば、10体の専門エージェントを待機させると、LLM用のAIモデルやKVCacheのためのリソースを事前確保するだけでGPUリソースが枯渇する可能性もあります。しかし、実際には、エージェント全員が同時に、一斉にGPUリソースを使ってタスクを実行し続けているわけではありません。
「必要な瞬間だけメモリを使い、不要な時は即座に解放する」
OSの仮想メモリ管理によって行ってきた、自然なリソース管理機能をGPUのメモリに対して実現する。それが今回検証したUC Berkeley Sky Computing Lab発のOSS、**kvcached**の本質的価値です。
https://github.com/ovg-project/kvcached
2. 検証環境とツールチェーン
今回は「GPUメモリ制約下でのマルチモデル並列稼働」をテーマに、kvcached の挙動を解析しました。検証にあたり、kvcachedプロジェクトの標準ツールに加えて独自のベンチマークツールも作成して利用しています。
検証環境
- Models:
meta-llama/Llama-3.2-1B&Qwen/Qwen2.5-0.5B(同時稼働) - Engine: vLLM (kvcached統合版)
- Backend: CUDA 13.0 / Python 3.12
検証ハードウェア環境
| 項目 | スペック | 備考 |
| GPU | NVIDIA GeForce RTX 4080 | VRAM 約16GB (16376 MiB) |
| CPU | Intel Core i5-14600KF | 14コア (6P+8E) / 20スレッド |
| メモリ (RAM) | 98 GiB | |
| OS | Ubuntu 24.04.3 LTS |
使用したツール群
kvctl/kvtop(Official): プロジェクトに含まれている共有kvcacheメモリセグメントを監視するCLI/TUIツール。kvbench(In-house Custom Tool): 今回の検証用に開発したツール。vLLMでの処理性能、GPUメモリ/KVキャッシュの消費量を時系列グラフとして可視化します。
3. 環境セットアップ
Step 1: vLLM+kvcachedのセットアップ
こちらを参考にセットアップしてください。
https://github.com/ovg-project/kvcached/blob/main/README.md
ここでは、Install from source の手順に従いました。
# under the project root folder
pip install -e . --no-build-isolation --no-cache-dir
python tools/dev_copy_pth.py
インストールされたkvcached/vLLM、それぞれのバージョンは以下の通りでした。
vLLM 0.14.1
kvcached 0.1.3Step 2: 共有メモリ空間の定義
Model A (Llama-3.2-1B) の起動:
export ENABLE_KVCACHED=true
export KVCACHED_AUTOPATCH=1
export KVCACHED_IPC_NAME=BENCH
python -m vllm.entrypoints.openai.api_server
--model meta-llama/Llama-3.2-1B
--port 12346
--gpu-memory-utilization 0.35
--no-enable-prefix-caching
--max-model-len 4096
--disable-log-requests
--host localhostModel B (Qwen2.5-0.5B) の起動:
export ENABLE_KVCACHED=true
export KVCACHED_AUTOPATCH=1
export KVCACHED_IPC_NAME=BENCH
python -m vllm.entrypoints.openai.api_server
--model Qwen/Qwen2.5-0.5B
--port 12347
--gpu-memory-utilization 0.35
--no-enable-prefix-caching
--max-model-len 4096
--disable-log-requests
--host localhostベンチマーククライアント(負荷生成)の起動
下記の2つのベンチマークコマンドをバックグラウンドで並列実行しました。
# Llama用クライアン ト vllm bench serve --model meta-llama/Llama-3.2-1B --port 12346 --num-prompts 100 --request-rate 5.0
# Qwen用クライアン
ト
vllm bench serve
--model Qwen/Qwen2.5-0.5B
--port 12347
--num-prompts 100
--request-rate 5.04. Analysis:kvbench で見たkvcachedの動作の確認
標準的な事前割り当て(Pre-allocation)方式では、物理メモリの量を超えるとvLLMプロセス自体が起動できない一方で、kvcachedが仮想的なGPUメモリの管理を行うことで、より高いプロセス密度(高集積化)を実現し、推論レイテンシを低減します。
こうした明確なメリットを踏まえながら、本評価では、KVCacheの総量がGPUの物理メモリ内に収まるよう構成しています。
このような構成で、実測のデータから明らかになることについて解説します。
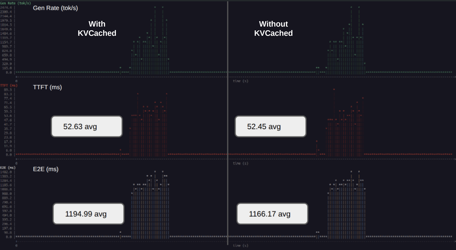
以下のグラフがkvbench による計測結果(タイムライングラフ)です。 左側が kvcached 有効、右側が無効(通常)の状態です。
① アイドル時のGPU Memoryの使用量を18.4%削減

グラフの「GPU Memy」をご覧ください。
- Without kvcached: 常に 16.38 GB (ほぼ上限) で張り付いています。アイドル時もメモリを抱え込んでいます。
- With kvcached: ピーク時でも 13.36 GB。約18.4%の削減 を達成しました。
② パフォーマンスを犠牲にすることなくリソース効率を向上
kvcached の有効時と無効時における時系列グラフを比較します。
E2E(End to End)、ITL(Inter Token Latency)、TTFT(Time To First Token)の平均値に注目すると、kvcached の有効化に伴い E2E と ITL で
約 2% の変動(E2E: 1194.99 と 1166.17、ITL: 9.00 と 8.81)が見られました。一方で、TTFT への影響はわずか 0.3%(52.63 と 52.45)であり、
無視できるレベルでした。
これらの数値は測定誤差の範囲内に収まっているため、kvcached の導入による実質的なパフォーマンスの低下は発生していないと結論づけています。

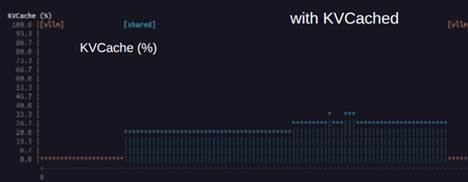
③アイドル状態のGPU Memory使用状況の考察
KVcached 有効で負荷がない状態
- Llama: Weights 2.0GB + Overhead 2.5GB = 4.5 GB
- Qwen: Weights 1.0GB + Overhead 2.7GB = 3.6 GB
- KVCache Pool: 3.09 GB (仮想予約、物理使用 0)
- vLLM 合計: 8.1 GB
上記のうち、KVCache Poolについては、アイドル時は物理的なメモリは実際には使用されていません。必要になったときに、予約された仮想メモリ空間に対して物理メモリをオンデマンドでマッピングして使用することになります。複数のAIモデルを扱うLLM推論サーバへのリクエストが疎(Sparse)である場合は、GPU Memoryを融通しあうことで、多量の物理メモリを消費することなく対応することができます。
KVcached 無効で負荷がない状態
- Llama: Weights 2.0GB + Overhead 2.5GB + KV 1.5GB = 6.0 GB
- Qwen: Weights 1.0GB + Overhead 2.7GB + KV 2.6GB = 6.3 GB
- vLLM 合計: 12.3 GB (+4.2 GB = KV事前割当分)
一方で、kvcachedが無効である場合は、各モデルに対応するLLMサーバが、それぞれKVCache領域を事前確保することになるため、負荷がない状態から、多くのGPU Memoryを消費していることがわかります。
5. 結論:Agent Swarm 実現のため高効率メモリ管理レイヤー
KVCacheという技術自体は、登場から一定の時間が経過しており、いまや目新しいものではありません。しかし、それをシステムレベルで抽象化し、GPUリソースのオンデマンドで細粒度なTime-sharing(時分割利用) を可能にしようとする kvcached のアプローチは、LLMインフラを構築する際には、必須な技術のひとつになり得ます。
私達、ミドクラがめざす「多数の専門エージェントが協調する世界」において、この技術は次のような価値をもたらす可能性があります。
- Over-subscription: https://sakana.ai/ab-mcts/による(Multi-LLM AB-MCTS)のように、異なるLLM AIモデルを活用して、多くのAI Agentによるタスク処理が実行されることを考えと、特にローカルLLMのようなGPUメモリ制約の大きい環境でも、多数のエージェントをインスタンス化しやすくなる。
- Resource Recycling: 思考していないエージェントのメモリを、思考中のエージェント側に優先的に回せる。
これは単なるコスト削減ツールという枠にとどまりません。フィジカルAIやエッジデバイスといったリソース制約の厳しい環境で、高度な群知能(Agent Swarm)を実現していくうえで、有望なAI時代のOS機能的な役割を担いうる技術だと考えています。
今後も私たちは、こうした基盤技術の検証と開発を継続し、AIエージェントの実用化を着実に前進させていきます。