


1. イントロダクション:AIエージェントに知識を与える
前回の記事では、MCPによるエージェントの能力拡張について、エッジAIセンサーとの統合事例を紹介しました。 エージェントに「知覚」を与えることで、物理世界の情報をリアルタイムに活用できることが示されました。
しかし、企業内のユースケースのように、AIエージェントを信頼して利用するためには、 企業固有の知識――技術ドキュメント、意思決定の経緯、様々な非構造化データ――を エージェントに正確に与え、ハルシネーション(幻覚)のリスクを低減することが不可欠です。
AIエージェントが回答した内容が事実と異なる――これは企業環境では致命的です。RAG(Retrieval-Augmented Generation)はこの課題に対する有力なアプローチですが、従来のベクトル検索ベースのRAGでは、 チャンク単位の検索ゆえにエンティティ間の関係性が失われ、情報の断片化がハルシネーションの一因に なりうると指摘されています。
本記事では、ナレッジグラフとベクトル検索を組み合わせることで、エージェントに与える知識の精度と網羅性を高め、ハルシネーションのリスク低減を目指すアプローチを紹介します。
グラフとは何か?
本記事で扱う「グラフ」とは、エンティティ(ノード)とそれらのリレーションシップ(エッジ)を構造的に表現する データ構造です。例えば、「技術Aを開発したのは企業B」「技術Aは技術Cに依存している」といった情報を、 ノード(技術A・企業B・技術C)とリレーションシップ(開発・依存)として可視化・管理できます。
グラフ構造を用いることで、単なるテキストやリストでは捉えきれない複雑な関係性やネットワーク全体の構造を把握できるのが特徴です。
さらに、グラフで表現されたノードやリレーションシップは、元ドキュメントなどの根拠に基づく「事実」として構造化されています。従来のRAGでは、断片化されたチャンクからAIが情報を補完する際、存在しない関係性を推測してしまうことがありました。一方、グラフ構造ではエンティティ間の関係が明示的に記録されるため、AIはドキュメントに実在する構造化された事実のみを参照でき、誤った情報を生成するリスクが低減されます。
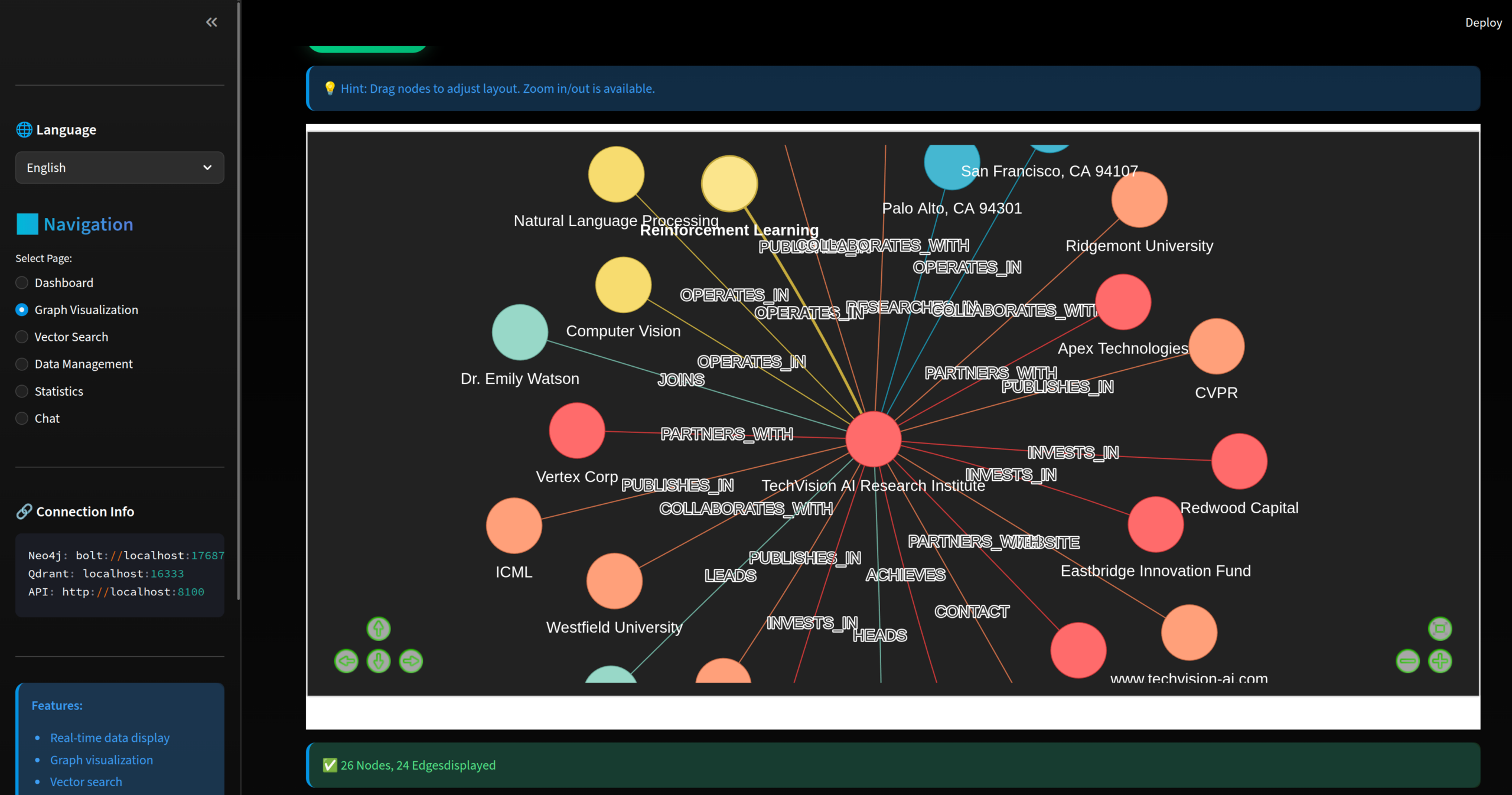
本記事で紹介するPoCシステムのスクリーンショットです。PDF文書を分析してナレッジグラフを抽出・可視化した様子です。
背景:GraphRAG と LightRAG
GraphRAG(Microsoft Research, 2024)は、ドキュメントからナレッジグラフを構築し、Leidenアルゴリズムによるコミュニティ検出でエンティティをクラスタリングします。各コミュニティごとに要約を生成することで、「このドキュメント群の主要テーマは何か」といったグローバルな質問にも対応できます。ただし、ナレッジグラフやインデックス構築時の処理コストが課題となることが指摘されています。
LightRAG(Guo et al., 2024, 香港大学)は、このコスト問題に対処した研究です。エンティティレベル(Local)と関係性レベル(Global)の二重検索によって、グラフ全体の再構築を不要としつつ、網羅性を実現しています。さらに、インクリメンタル更新にも対応しており、ドキュメント追加時に効率的なグラフ更新が可能です。
本記事では、LightRAGのアーキテクチャをベースに、エンタープライズ用途に必要な拡張を加えて行ったPoCシステムについて解説します。
2. PoCシステムの概要
2.1. 拡張ポイント
- 6つの検索モード: 用途に応じて精度と速度のバランスを選択できる、柔軟な検索オプションを実装しています。特に、LLMを一切使用しないKeyword検索は、瞬時の応答が求められる用途で極めて高速です。
- オントロジー駆動の抽出: ドメイン固有の知識(オントロジー)をYAMLで定義し、LLMによるエンティティ・リレーションシップ抽出の品質と一貫性を向上させます。これにより、専門的なドキュメントでも構造化された知識を正確に抽出できます。
- エンタープライズ・ガバナンス: データ系譜(Data Lineage)と監査ログ機能を実装し、ナレッジグラフ内のすべての情報が「いつ、どのドキュメントから生成されたか」を追跡可能にします。これにより、AIの回答の根拠を常に検証できます。
2.2. ローカルファースト設計
企業用途では、機密情報が外部に出ないことが絶対条件です。本PoCシステムは、ローカル環境で動作するLLMサーバ Ollama を活用することで、完全なデータプライバシーを保証します。
これにより、以下のメリットがもたらされます。
- データプライバシー: 機密ドキュメントが社外に出ない
- レイテンシ: ネットワーク往復を排除し、推論応答を高速化
- コスト予測性: API従量課金ではなく、固定的なインフラコスト
- オフライン動作: ネットワーク障害時もシステムが稼働
前回の記事で紹介した「Skillsの時代」の文脈では、こうしたローカル実行可能な小規模モデルとドメイン特化の知識基盤の組み合わせが、 エンタープライズAIの現実的な展開パスとなると考えています。
3. システムアーキテクチャ
3.1. 全体構成
PoCとして構築したシステムは以下のコンポーネントで構成されます。
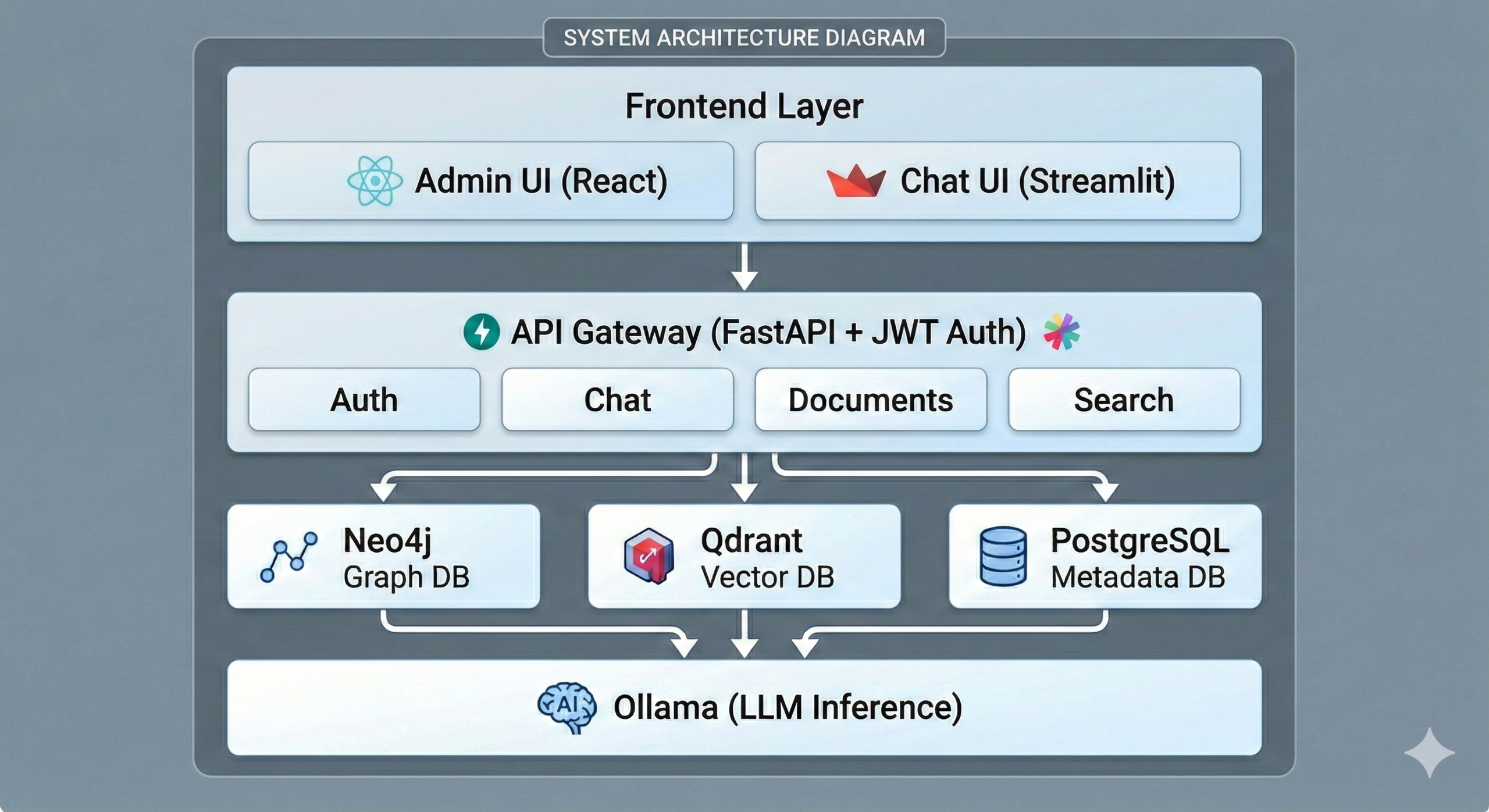
FastAPIバックエンドを中心に、グラフDB(Neo4j)・ベクトルDB(Qdrant)・メタデータDB(PostgreSQL)・LLM推論(Ollama)が連携し、フロントエンドのStreamlit UIからAPIを通じて各機能にアクセスする構成です。
3.2. 技術スタック
| コンポーネント | 技術 | 役割 |
| グラフDB | Neo4j 5.14 Community | エンティティ・関係性の構造化保存 |
| ベクトルDB | Qdrant | セマンティック類似度検索 |
| メタデータDB | PostgreSQL 16 | ユーザー管理、チャット履歴、監査ログ |
| LLM推論 | Ollama + qwen2.5:7b | エンティティ抽出、検索、回答生成 |
4. ナレッジグラフ構築パイプライン
4.1. 処理フロー
ドキュメントからナレッジグラフを自動構築するパイプラインは、以下の段階で構成されます:
ドキュメント入力 (PDF / Markdown / Text) │ ▼ [パーサー] テキスト・メタデータ抽出 │ ▼ [チャンカー] トークンベースのセマンティック分割 │ ▼ [エンティティ抽出] LLMによる固有表現認識 │ 例) Person, Organization, Technology, Concept, │ Product, Project, Dataset, API │ ▼ [関係性抽出] LLMによるエンティティ間関係(リレーションシップ)の推定・抽出 │ 例) USES, DEPENDS_ON, IMPLEMENTS, CREATED, WORKS_AT, ... │ ▼ [永続化] ├── Neo4j: ノード・エッジの作成/マージ └── Qdrant: エンティティ・関係性・チャンクのベクトル保存
4.2. LLMによるエンティティ抽出
エンティティ抽出にはLLMを使用し、構造化されたフォーマットで出力を取得します。LLMの出力をパースし、事前に定義されたエンティティタイプや、 事前選択されたオントロジーにしたがってエンティティとして抽出します。
class KnowledgeGraphBuilder: TUPLE_DELIMITER = "<|#|>" DEFAULT_ENTITY_TYPES = [ "Person", "Organization", "Technology", "Concept", "Location", "Event", "Product", "Method", ]
事前にオントロジーが選択されている場合、上記のDEFAULT_ENTITY_TYPESが上書きされます。例として、技術ドメインオントロジー(tech_domain.yaml)では、Person, Organization, Technology, Concept, Product, Project, Dataset, API の8タイプが定義されています。
4.3. Neo4jとQdrantによるデータ永続化
抽出されたエンティティとリレーションシップはNeo4jに保存されます。同名のエンティティは自動的に統合され、重複ノードの増殖を防ぎます。 また、Qdrantの3つのコレクションに、ベクトル埋め込みが保存されます。
| コレクション | 内容 |
entities |
エンティティの意味表現 |
relationships |
関係性の意味表現 |
chunks |
テキストチャンクの意味表現 |
このナレッジグラフ構造(Neo4j)とベクトル空間(Qdrant)の二重表現が、後述する6つの検索モードの基盤となります。
4.4. データ登録、ナレッジグラフ作成の様子
ここまで説明してきた内容を踏まえて、
- データの登録
- ナレッジグラフ作成前のオントロジー選択
- ナレッジグラフの構築と可視化
それぞれについて、スクリーンショットを交えて紹介します。
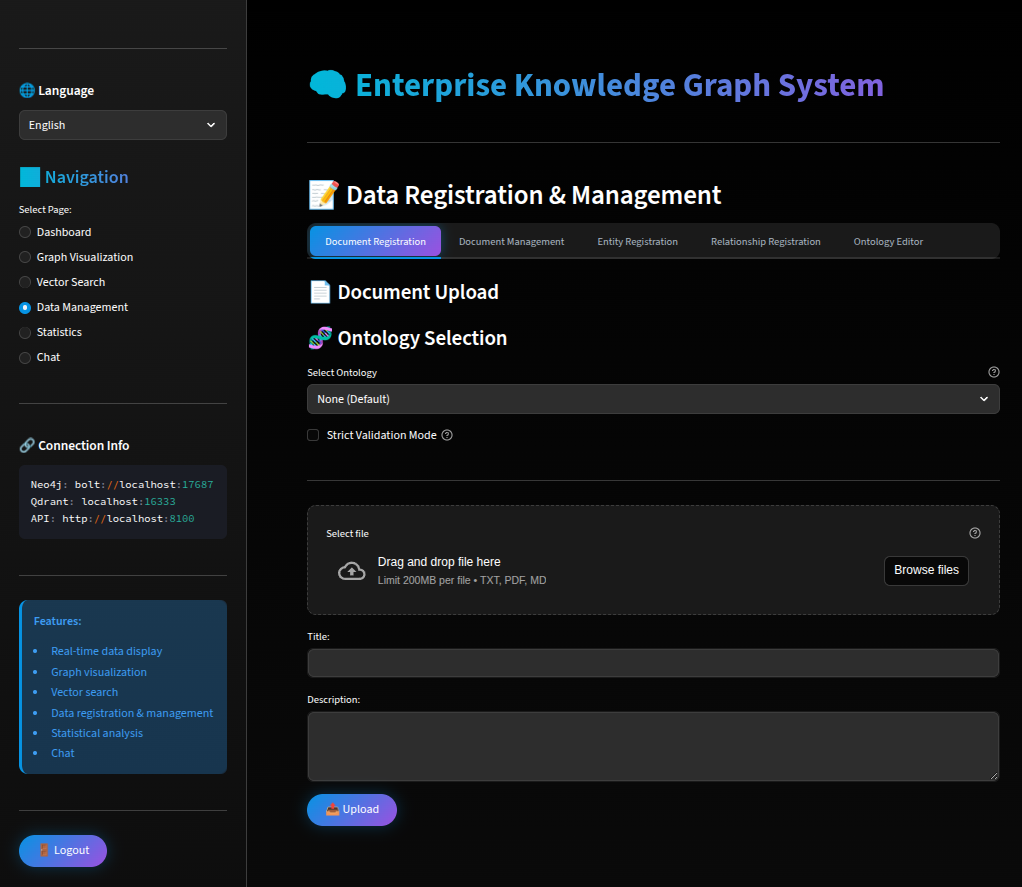
本画面からユーザがドキュメントを登録します。PDF文書、テキストファイル、Markdownファイルをアップロードすることができます。
近年は、企業内の構造化されていない文書から得られるナレッジを活用したいニーズが高まっています。 そのため今後は、より多様な文書フォーマットへの対応や、OCR(Optical Character Recognition)・VLM(Vision Language Model)を 用いた文書・画像解析を組み合わせ、文書内に埋め込まれた様々な情報や文書構造を抽出するなど、より高度な文書理解が求められ ています。
今回は、そこまでの複雑な文書解析は行わず、ファイルからのテキスト抽出のみを実施しました。
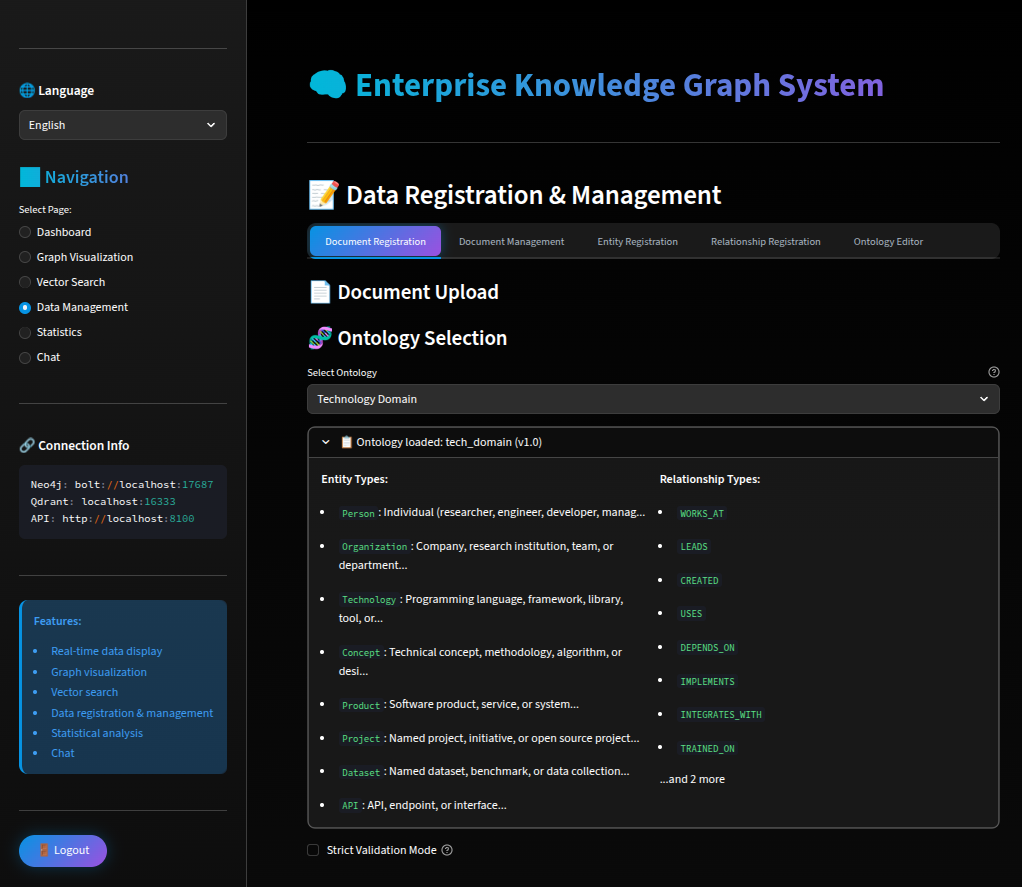
オントロジーの選択画面です。利用用途や対象業界に合わせて、事前に定義されたオントロジーの中からEntity TypeとRelationship Typeを選択できます。
業界ごとに慣用されるEntity TypeやRelationship Typeが存在するため、あらかじめ類義語を定義・統一しておくことで、ナレッジグラフの一貫性(正規化)を高め、より扱いやすいグラフを構築できます。
さらに、既存のオントロジー資産を活用したい場合は、外部エディタで作成した定義をW3C標準のOWL/RDF形式などのファイルとしてインポートすることもできます。
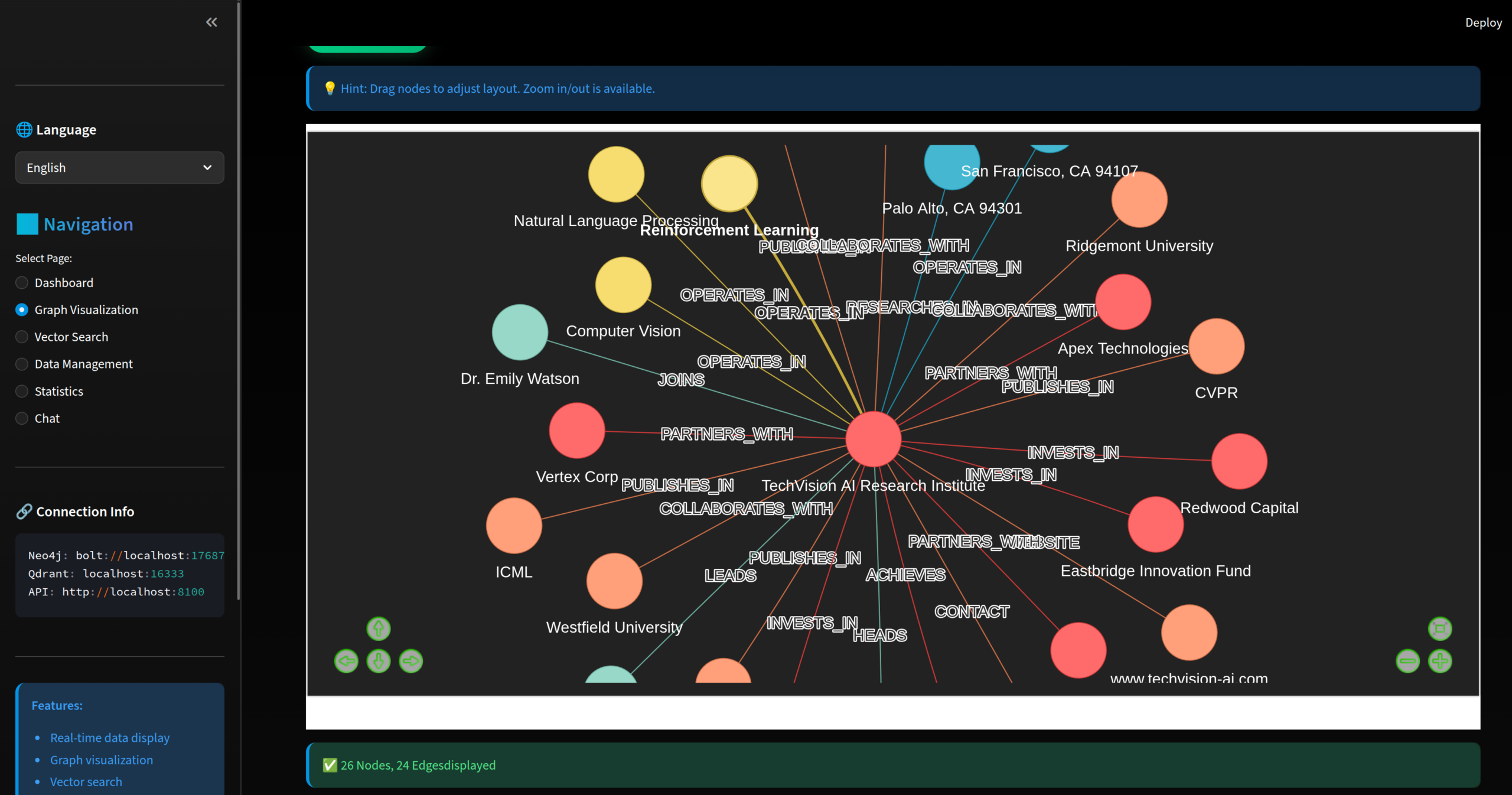
得られたKnowledge Graphを可視化したものです。ノード(丸)がEntityを表しており、Entity Typeごとに色分けされています。 また、各Entity間を結ぶエッジ(線)にはRelationship Typeが表示されています。
このスクリーンショットでは、中心に架空の組織が配置され、その周辺にはその組織をリードする人物が「LEADS」、パートナー関係にある大学や企業が「PARTNERS_WITH」、さらに「ACQUIRED_BY」などのRelationship Typeで接続されたEntityが見られます。
このように、オントロジーに則って構築されたKnowledge Graphはエンティティ間の関係性を構造化して表現します。RAGシステムではこの関係情報をプロンプトに 組み込むことで、LLMのハルシネーションリスクの低減が期待できます。
5. 6つの検索モード
用途に応じて6つの検索モードを切り替え可能にしました。いずれのモードも、Qdrant や Neo4j を通じてユーザクエリに関連するデータを抽出し、プロンプトと合わせてLLMに入力して回答文を生成します。以下に各モードを解説します。
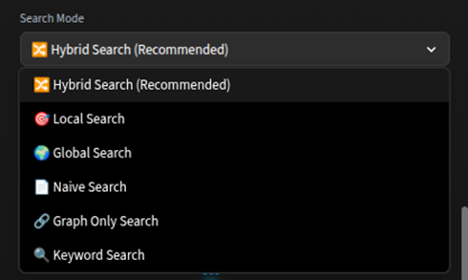
チャットUIの検索モード選択画面。ドロップダウンから目的に応じたモードを選択できます。
- Local検索: クエリ内のエンティティを起点に、その周辺のサブグラフを局所的に探索します。プロンプトのコンテキストは、Qdrantによるベクトル検索で取得した、意味的に類似するテキストチャンクで補完されます。「Xとは何か」といった特定のエンティティに関する質問に適しています。
- Global検索: グラフ全体の構造を考慮し、コミュニティ構造に基づいて広範なコンテキストを収集します。Local検索同様、プロンプトのコンテキストは、ベクトル検索で取得した、意味的に類似するテキストチャンクで補完されます。「このドキュメント群の主要テーマは何か」といった俯瞰的な質問に適しています。
- Hybrid検索(推奨): Local検索とGlobal検索を組み合わせ、局所的な精度と全体的な網羅性を両立します。
- Naive検索: グラフ構造を利用せず、ベクトル類似度のみで検索する従来型のRAGです。性能比較のベースラインとして機能します。
- GraphOnly検索: ベクトル検索は使わず、Neo4jのグラフ構造のみを深さ優先探索(DFS)で辿ります。つまり、プロンプトは明示的に記録された関係だけで構成されます。エンティティ間の明示的な関係を追跡したい場合に有効です。
- Keyword検索: Neo4jの全文インデックス(Luceneベース)を利用した最速の検索モードです。LLM推論を必要とせず、既知のエンティティ名による高速な検索やオートコンプリートに適しています。
ここでは定性的な比較を行います。忠実性・関連性・回答の完全性などの 指標による定量的な評価は、今後の課題として計画しています。
| Mode | 回答までの時間 | コンテキストの豊富さ | LLM 生成回数 (qwen2.5) | エンベディング回数 (nomic-embed-text) |
| Keyword検索 | 高速 (LLM利用なし) | 少ない(名前一致のみ) | 0 | 0 |
| GraphOnly検索 | ミディアム | 構造化された関係性のみ | 1 (エンティティ抽出) | 0 |
| Naive検索 | ミディアム | テキストチャンク(構造なし) | 0 | 1 (クエリ エンベディング) |
| Local検索 | 比較的遅い | グラフ+テキストチャンク | 1 (エンティティ抽出) | 1 (クエリ エンベディング) |
| Global検索 | 比較的遅い | コミュニティ+テキストチャンク | 0 | 1 (クエリ エンベディング) |
| Hybrid検索 | 遅い | 最も包括的 | 1 (ローカルエンティティ抽出) | 2 (Local検索、Global検索, それぞれ1回ずつ) |
すべてのモードでドキュメントフィルタリングがサポートされており、特定のドキュメント群に対象を絞った検索が可能です。これにより、マルチテナントやプロジェクトスコープの検索が実現できます。
6. チャットUI ― Streamlitによる対話型インターフェース
チャットUIはStreamlitで構築されており、以下の機能を提供します:
- 検索モード選択:ドロップダウンで6つのモードを切り替え
- ドキュメント管理:アップロード、登録/解除、ステータス追跡
- ドキュメントフィルタリング:検索対象ドキュメントの選択
- メトリクスダッシュボード:ノード数、エッジ数、関連度スコアのリアルタイム表示
- 多言語対応:日本語/英語のUI切り替え
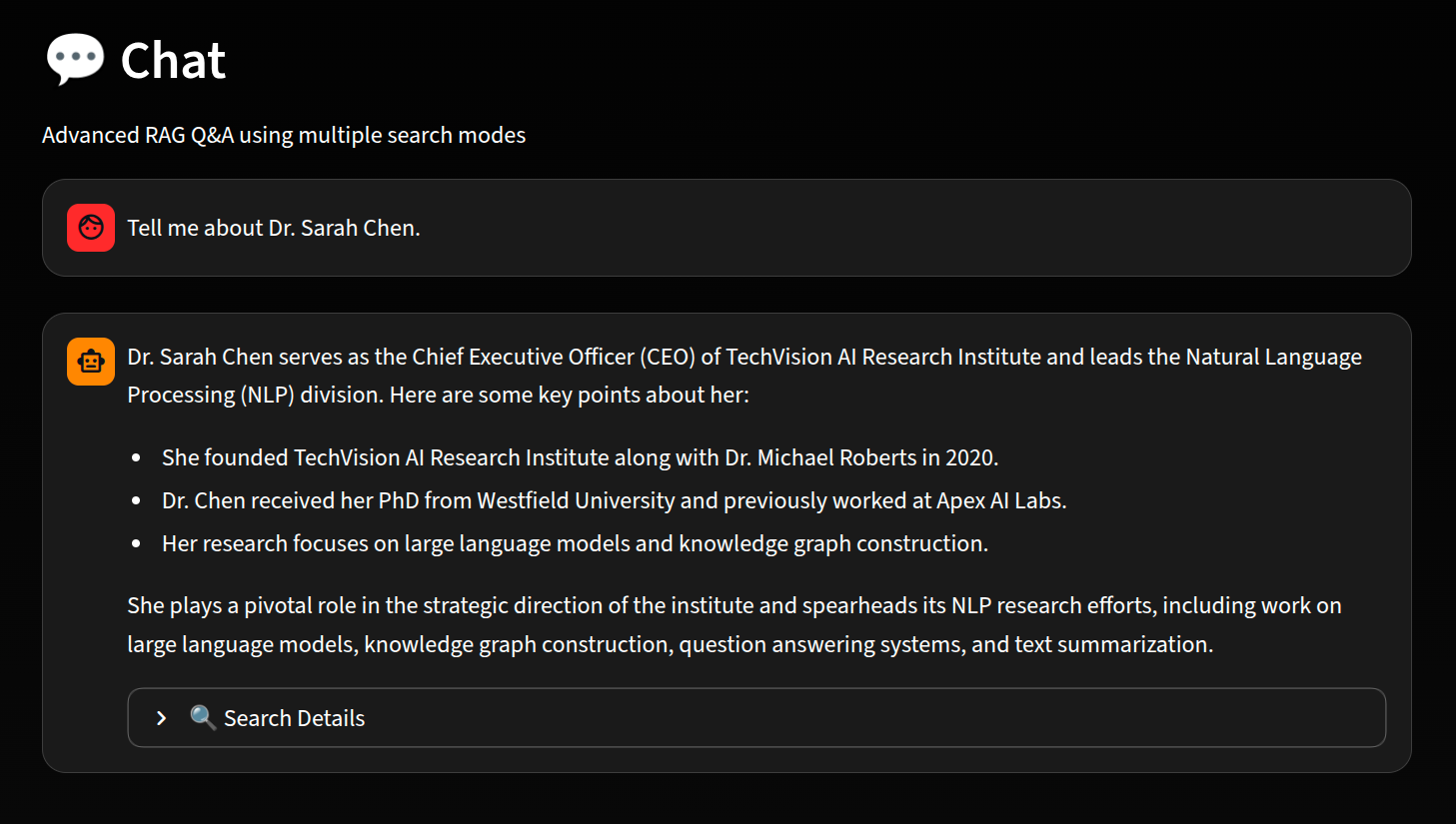
Knowledge Graphから得られた情報をもとに、人物に関する詳細が回答として提示されています。

様々な検索モード間の出力の比較もできるようにしました。比較結果については、ここでの詳細な説明は割愛します。
7. エージェント統合とMCPへの展望
前回の記事で紹介したMCPの文脈では、本システムはナレッジグラフ検索をMCPツールとして公開することで、 AIエージェントに「正確な知識」を与えることができます。
7.1. マルチエージェント環境での役割
エージェントの協調動作において、ナレッジグラフシステムは以下のような役割を果たします:
[Orchestrator Agent] │ ├─ [Edge AI Sensor Agent] (MCP) │ └─ 物理世界の「知覚」を提供 │ ├─ [Knowledge Graph Agent] (MCP) │ └─ 蓄積された「知識」を提供 │ └─ 6つの検索モードを使い分け │ └─ [Analysis Agent] └─ 知覚 + 知識を統合して判断
例えば製造現場では、Edge AIが検出した異常パターンに対して、ナレッジグラフから過去の類似事例や対処手順を検索し、オーケストレーターが総合的な判断を行う、といったワークフローが実現できます。
8. まとめ:エージェントに正確な知識を与える
特化型AIエージェントが企業で信頼を得るには、ハルシネーションの抑制が避けて通れない課題です。本記事では、ナレッジグラフとベクトル検索の組み合わせにより、エージェントに与える知識の精度と追跡可能性を高めるアプローチを紹介しました。
グラフ構造はエンティティ間の関係を明示的に保持するため、ベクトル検索のみのRAGと比較して、根拠のない情報がコンテキストに紛れ込むリスクを構造的に下げることができます。さらにデータ系譜により「この回答はどのドキュメントのどの記述に基づくか」を常に追跡でき、回答の検証可能性を担保します。
こうした検証可能な知識基盤を、前回紹介したMCPのようなエージェント統合技術と組み合わせることで、企業が安心して利用できる信頼性の高いAIエージェントシステムの構築が期待されます。
参考情報
- GraphRAG ー Microsoft GraphRAG project
- LightRAG: Simple and Fast Retrieval-Augmented Generation – GraphRAGを軽量化した検索アーキテクチャ
- Neo4j Graph Database – グラフデータベース
- Qdrant Vector Database – ベクトルデータベース
- Ollama – ローカルLLM推論エンジン
- MCPによるエージェントの能力拡張 – 前回のMCP記事
- Skillsの時代の到来 – 特化型AIエージェントとインフラ